
# 数据类型
在 Go 编程语言中,数据类型用于声明函数和变量。
数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存。具体分类如下:
类型 详解 布尔型 布尔型的值只可以是常量 true 或者 false。 数字类型 整型 int 和浮点型 float。Go 语言支持整型和浮点型数字,并且支持复数,其中位的运算采用补码。 字符串类型 字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。 派生类型 (a) 指针类型(Pointer)(b) 数组类型© 结构化类型(struct)(d) Channel 类型(e) 函数类型(f) 切片类型(g) 接口类型(interface)(h) Map 类型
| 类型 | 详解 |
|---|---|
| 布尔型 | 布尔型的值只可以是常量 true 或者 false。 |
| 数字类型 | 整型 int 和浮点型 float。Go 语言支持整型和浮点型数字,并且支持复数,其中位的运算采用补码。 |
| 字符串类型 | 字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。 |
| 派生类型 | (a) 指针类型(Pointer)(b) 数组类型 (c) 结构化类型(struct)(d) Channel 类型(e) 函数类型(f) 切片类型(g) 接口类型(interface)(h) Map 类型 |
# 定义变量
# 变量没有初始化
在go语言中定义了一个变量,指定变量类型,如果没有初始化,则变量默认为零值。零值就是变量没有做初始化时系统默认设置的值。
| 类型 | 零值 |
|---|---|
| 数值类型 | 0 |
| 布尔类型 | false |
| 字符串 | “”(空字符串) |
# 1. 变量没有指定类型
var name = "zhangsan"
# 2. 带类型
var name string = "zhangsan"
# 3. 类型推导方式定义变量
a在函数内部,可以使用更简略的 := 方式声明并初始化变量
注意:短变量只能用于声明局部变量,不能用于全局变量声明
intVal := 1相等于:
var intVal int
intVal =1
# 4. 声明多个变量
可以同时声明多个类型相同的变量(非全局变量),如下图所示:
var x, y int
var c, d int = 1, 2
g, h := 123, "hello"
类型不一样的变量
var (
a int
b bool
)
# 匿名变量
匿名变量的特点是一个下画线_,这本身就是一个特殊的标识符,被称为空白标识符。它可以像其他标识符那样用于变量的声明或赋值(任何类型都可以赋值给它),但任何赋给这个标识符的值都将被抛弃,因此这些值不能在后续的代码中使用,也不可以使用这个标识符作为变量对其它变量进行赋值或运算。
使用匿名变量时,只需要在变量声明的地方使用下画线替换即可。
func GetData() (int, int) {
return 10, 20
}
func main(){
a, _ := GetData()
_, b := GetData()
fmt.Println(a, b)
}
# 变量作用域
作用域指的是已声明的标识符所表示的常量、类型、函数或者包在源代码中的作用范围,在此我们主要看一下go中变量的作用域,根据变量定义位置的不同,可以分为一下三个类型:
函数内定义的变量为局部变量,这种局部变量的作用域只在函数体内,函数的参数和返回值变量都属于局部变量。这种变量在存在于函数被调用时,销毁于函数调用结束后。
函数外定义的变量为全局变量,全局变量只需要在一个源文件中定义,就可以在所有源文件中使用,甚至可以使用import引入外部包来使用。全局变量声明必须以 var 关键字开头,如果想要在外部包中使用全局变量的首字母必须大写。
函数定义中的变量成为形式参数,定义函数时函数名后面括号中的变量叫做形式参数(简称形参)。形式参数只在函数调用时才会生效,函数调用结束后就会被销毁,在函数未被调用时,函数的形参并不占用实际的存储单元,也没有实际值。形式参数会作为函数的局部变量来使用。
# 基本类型
| 类型 | 描述 |
|---|---|
| uint8 / uint16 / uint32 / uint64 | 无符号 8 / 16 / 32 / 64位整型 |
| int8 / int16 / int32 / int64 | 有符号8 / 16 / 32 / 64位整型 |
| float32 / float64 | IEEE-754 32 / 64 位浮点型数 |
| complex64 / complex128 | 32 / 64 位实数和虚数 |
| byte | 类似 uint8 |
| rune | 类似 int32 |
| uintptr | 无符号整型,用于存放一个指针 |
有了数据类型,我们就可以使用这些类型来定义变量,Go 语言变量名由字母、数字、下划线组成,其中首个字符不能为数字。
# 指针
与C相同,Go语言让程序员决定何时使用指针。变量其实是一种使用方便的占位符,用于引用计算机内存地址。Go 语言中的的取地址符是&,放到一个变量前使用就会返回相应变量的内存地址。
指针变量其实就是用于存放某一个对象的内存地址。
# 指针声明和初始化
和基础类型数据相同,在使用指针变量之前我们首先需要申明指针,声明格式如下:var var_name var-type,其中的var-type 为指针类型,var_name 为指针变量名, 号用于指定变量是作为一个指针。
var ip *int /* 指向整型*/
var fp *float32 /* 指向浮点型 */
指针的初始化就是取出相对应的变量地址对指针进行赋值,具体如下:
var a int= 20 /* 声明实际变量 */
var ip *int /* 声明指针变量 */
ip = &a /* 指针变量的存储地址 */
# 空指针
当一个指针被定义后没有分配到任何变量时,它的值为 nil,也称为空指针。它概念上和其它语言的null、NULL一样,都指代零值或空值。
# 数组
和c语言相同,Go语言也提供了数组类型的数据结构,数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。
# 声明数组
Go 语言数组声明需要指定元素类型及元素个数,语法格式如下:
var variable_name [SIZE] variable_type
var balance [10] float32
# 初始化数组
数组的初始化方式有不止一种方式,我们列举如下:
直接进行初始化:var balance = [5] float32 {1000.0, 2.0, 3.4, 7.0, 50.0}
通过字面量在声明数组的同时快速初始化数组:balance := [5] float32 {1000.0, 2.0, 3.4, 7.0, 50.0}
数组长度不确定,编译器通过元素个数自行推断数组长度,在[ ]中填入...,举例如下:var balance = [...] float32 {1000.0, 2.0, 3.4, 7.0, 50.0}和balance := [...] float32 {1000.0, 2.0, 3.4, 7.0, 50.0}
数组长度确定,指定下标进行部分初始化:balanced := [5] float32 (1:2.0, 3:7.0)
初始化数组中 {} 中的元素个数不能大于 [] 中的数字。 如果忽略 [] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大小。
# go中的数组名意义
在c语言中我们知道数组名在本质上是数组中第一个元素的地址,而在go语言中,数组名仅仅表示整个数组,是一个完整的值,一个数组变量即是表示整个数组。
所以在go中一个数组变量被赋值或者被传递的时候实际上就会复制整个数组。如果数组比较大的话,这种复制往往会占有很大的开销。所以为了避免这种开销,往往需要传递一个指向数组的指针,这个数组指针并不是数组。关于数组指针具体在指针的部分深入的了解。
# 数组指针
通过数组和指针的知识我们就可以定义一个数组指针
var a = [...]int{1, 2, 3} // a 是一个数组
var b = &a // b 是指向数组的指针
数组指针除了可以防止数组作为参数传递的时候浪费空间,还可以利用其和for range来遍历数组,具体代码如下:
for i, v := range b { // 通过数组指针迭代数组的元素
fmt.Println(i, v)
}
# 数组遍历
- 方法1
// 第四种初始化数组的方法,指定下标
a := [...]int{1:1, 3:5}
for i := 0; i < len(a); i++ {
fmt.Print(a[i], " ")
}
- 方法2
// 第四种初始化数组的方法,指定下标
a := [...]int{1:1, 3:5}
for _, value := range a {
fmt.Print(value, " ")
}
# 二维数组
Go语言支持多维数组,我们这里以二维数组为例(数组中又嵌套数组):
var 数组变量名 [元素数量][元素数量] T
示例
// 二维数组
var array5 = [2][2]int{{1,2},{2,3}}
fmt.Println(array5)
# 数组遍历
二维数据组的遍历
// 二维数组
var array5 = [2][2]int{{1,2},{2,3}}
for i := 0; i < len(array5); i++ {
for j := 0; j < len(array5[0]); j++ {
fmt.Println(array5[i][j])
}
}
遍历方式2
for _, item := range array5 {
for _, item2 := range item {
fmt.Println(item2)
}
}
# 类型推导
另外我们在进行数组的创建的时候,还可以使用类型推导,但是只能使用一个 ...
// 二维数组(正确写法)
var array5 = [...][2]int{{1,2},{2,3}}
错误写法
// 二维数组
var array5 = [2][...]int{{1,2},{2,3}}
# 结构体
通过上述数组的学习,我们就可以直接定义多个同类型的变量,但这往往也是一种限制,只能存储同一种类型的数据,而我们在结构体中就可以定义多个不同的数据类型。
# 声明结构体
在声明结构体之前我们首先需要定义一个结构体类型,这需要使用type和struct,type用于设定结构体的名称,struct用于定义一个新的数据类型。具体结构如下:
type struct_variable_type struct {
member definition
member definition
...
member definition
}
定义好了结构体类型,我们就可以使用该结构体声明这样一个结构体变量
variable_name := structure_variable_type {value1, value2...valuen}
variable_name := structure_variable_type { key1: value1, key2: value2..., keyn: valuen}
# 访问结构体成员
如果要访问结构体成员,需要使用点号 . 操作符,格式为:结构体变量名.成员名
package main
import "fmt"
type Books struct {
title string
author string
}
func main() {
var book1 Books
Book1.title = "Go 语言入门"
Book1.author = "mars.hao"
}
# 结构体指针
关于结构体指针的定义和申明同样可以套用前文中讲到的指针的相关定义,从而使用一个指针变量存放一个结构体变量的地址。
定义一个结构体变量的语法:var struct_pointer *Books。
这种指针变量的初始化和上文指针部分的初始化方式相同struct_pointer = &Book1,但是和c语言中有所不同,使用结构体指针访问结构体成员仍然使用.操作符。格式如下:struct_pointer.title
# 字符串
一个字符串是一个不可改变的字节序列,字符串通常是用来包含人类可读的文本数据。和数组不同的是,字符串的元素不可修改,是一个只读的字节数组。每个字符串的长度虽然也是固定的,但是字符串的长度并不是字符串类型的一部分。
# 字符串定义和初始化
Go 语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、float32、float64等)一样。Go语言里的字符串的内部实现使用UTF-8编码。字符串的值为双引号(")中的内容,可以在Go语言的源码中直接添加非ASCll码字符,例如:
s1 := "hello"
s1 := "你好"
如果想要定义多行字符串,可以使用反引号
var str = `第一行
第二行`
fmt.Println(str)
# 字符串常见操作
- len(str):求长度
- +或fmt.Sprintf:拼接字符串
- strings.Split:分割
- strings.contains:判断是否包含
- strings.HasPrefix,strings.HasSuffix:前缀/后缀判断
- strings.Index(),strings.LastIndex():子串出现的位置
- strings.Join():join操作
- strings.Index():判断在字符串中的位置
# 字符串UTF8编码
根据Go语言规范,Go语言的源文件都是采用UTF8编码。因此,Go源文件中出现的字符串面值常量一般也是UTF8编码的(对于转义字符,则没有这个限制)。提到Go字符串时,我们一般都会假设字符串对应的是一个合法的UTF8编码的字符序列。
Go语言的字符串中可以存放任意的二进制字节序列,而且即使是UTF8字符序列也可能会遇到坏的编码。如果遇到一个错误的UTF8编码输入,将生成一个特别的Unicode字符‘\uFFFD’,这个字符在不同的软件中的显示效果可能不太一样,在印刷中这个符号通常是一个黑色六角形或钻石形状,里面包含一个白色的问号‘�’。
下面的字符串中,我们故意损坏了第一字符的第二和第三字节,因此第一字符将会打印为“�”,第二和第三字节则被忽略;后面的“abc”依然可以正常解码打印(错误编码不会向后扩散是UTF8编码的优秀特性之一)。
fmt.Println("\xe4\x00\x00\xe7\x95\x8cabc") // �界abc
# 字符串的强制类型转换
在上文中我们知道源代码往往会采用UTF8编码,如果不想解码UTF8字符串,想直接遍历原始的字节码:
可以将字符串强制转为[]byte字节序列后再行遍历(这里的转换一般不会产生运行时开销): 采用传统的下标方式遍历字符串的字节数组 除此以外,字符串相关的强制类型转换主要涉及到[]byte和[]rune两种类型。每个转换都可能隐含重新分配内存的代价,最坏的情况下它们的运算时间复杂度都是O(n)。
不过字符串和[]rune的转换要更为特殊一些,因为一般这种强制类型转换要求两个类型的底层内存结构要尽量一致,显然它们底层对应的[]byte和[]int32类型是完全不同的内部布局,因此这种转换可能隐含重新分配内存的操作。
要修改字符串,需要先将其转换成[]rune 或 []byte类型,完成后在转换成string,无论哪种转换都会重新分配内存,并复制字节数组
转换为 []byte 类型
// 字符串转换
s1 := "big"
byteS1 := []byte(s1)
byteS1[0] = 'p'
fmt.Println(string(byteS1))
转换为rune类型
// rune类型
s2 := "你好golang"
byteS2 := []rune(s2)
byteS2[0] = '我'
fmt.Println(string(byteS2))
# Slice
简单地说,切片就是一种简化版的动态数组。因为动态数组的长度不固定,切片的长度自然也就不能是类型的组成部分了。数组虽然有适用它们的地方,但是数组的类型和操作都不够灵活,而切片则使用得相当广泛。
切片高效操作的要点是要降低内存分配的次数,尽量保证append操作(在后续的插入和删除操作中都涉及到这个函数)不会超出cap的容量,降低触发内存分配的次数和每次分配内存大小。
# slice定义和声明
type SliceHeader struct {
Data uintptr // 指向底层的的数组指针
Len int // 切片长度
Cap int // 切片最大长度
}
和数组一样,内置的len函数返回切片中有效元素的长度,内置的cap函数返回切片容量大小,容量必须大于或等于切片的长度。
切片可以和nil进行比较,只有当切片底层数据指针为空时切片本身为nil,这时候切片的长度和容量信息将是无效的。如果有切片的底层数据指针为空,但是长度和容量不为0的情况,那么说明切片本身已经被损坏了
只要是切片的底层数据指针、长度和容量没有发生变化的话,对切片的遍历、元素的读取和修改都和数组是一样的。在对切片本身赋值或参数传递时,和数组指针的操作方式类似,只是复制切片头信息(reflect.SliceHeader),并不会复制底层的数据。对于类型,和数组的最大不同是,切片的类型和长度信息无关,只要是相同类型元素构成的切片均对应相同的切片类型。
声明切片类型的基本语法如下:
var name [] T
其中:
- name:表示变量名
- T:表示切片中的元素类型
举例
// 声明切片,把长度去除就是切片
var slice = []int{1,2,3}
fmt.Println(slice)
# 关于nil的认识
当你声明了一个变量,但却还并没有赋值时,golang中会自动给你的变量赋值一个默认的零值。这是每种类型对应的零值。
- bool:false
- numbers:0
- string:""
- pointers:nil
- slices:nil
- maps:nil
- channels:nil
- functions:nil
nil表示空,也就是数组初始化的默认值就是nil
var slice2 [] int
fmt.Println(slice2 == nil)
运行结果
true
# 切片的遍历
切片的遍历和数组是一样的
var slice = []int{1,2,3}
for i := 0; i < len(slice); i++ {
fmt.Print(slice[i], " ")
}
# 基于数组定义切片
由于切片的底层就是一个数组,所以我们可以基于数组来定义切片
// 基于数组定义切片
a := [5]int {55,56,57,58,59}
// 获取数组所有值,返回的是一个切片
b := a[:]
// 从数组获取指定的切片
c := a[1:4]
// 获取 下标3之前的数据(不包括3)
d := a[:3]
// 获取下标3以后的数据(包括3)
e := a[3:]
运行结果
[55 56 57 58 59]
[55 56 57 58 59]
[56 57 58]
[55 56 57]
[58 59]
同理,我们不仅可以对数组进行切片,还可以切片在切片
# 切片的长度和容量
切片拥有自己的长度和容量,我们可以通过使用内置的len)函数求长度,使用内置的cap() 函数求切片的容量。
切片的长度就是它所包含的元素个数。
切片的容量是从它的第一个元素开始数,到其底层数组元素末尾的个数。切片s的长度和容量可通过表达式len(s)和cap(s)来获取。
举例
// 长度和容量
s := []int {2,3,5,7,11,13}
fmt.Printf("长度%d 容量%d\n", len(s), cap(s))
ss := s[2:]
fmt.Printf("长度%d 容量%d\n", len(ss), cap(ss))
sss := s[2:4]
fmt.Printf("长度%d 容量%d\n", len(sss), cap(sss))
运行结果
长度6 容量6
长度4 容量4
长度2 容量4
为什么最后一个容量不一样呢,因为我们知道,经过切片后sss = [5, 7] 所以切片的长度为2,但是一因为容量是从2的位置一直到末尾,所以为4
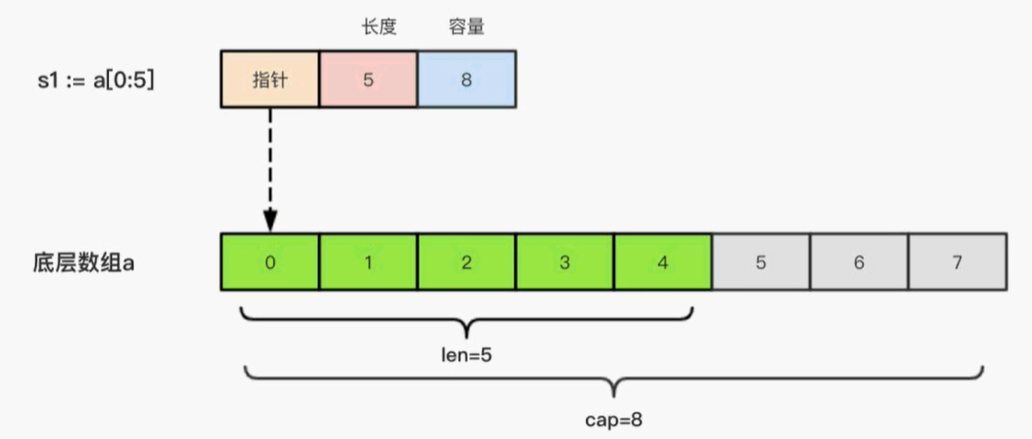
# 切片的本质
切片的本质就是对底层数组的封装,它包含了三个信息
- 底层数组的指针
- 切片的长度(len)
- 切片的容量(cap)
举个例子,现在有一个数组 a := [8]int {0,1,2,3,4,5,6,7},切片 s1 := a[:5],相应示意图如下
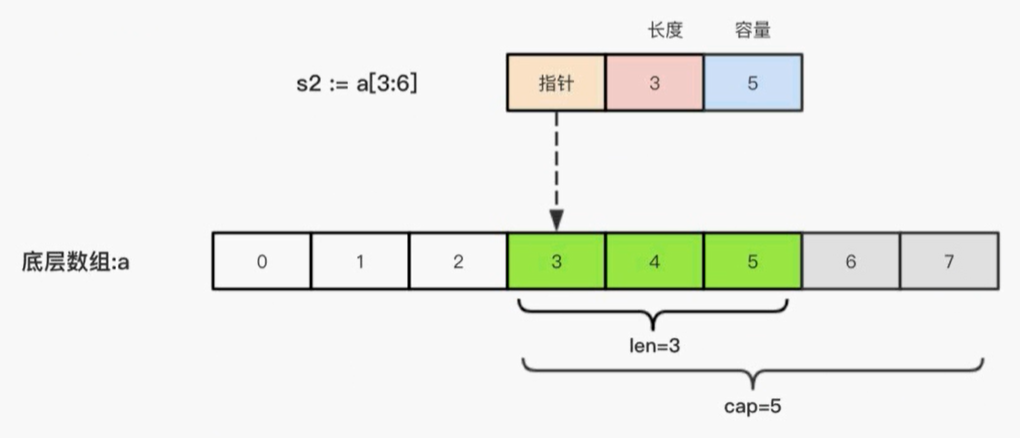
切片 s2 := a[3:6],相应示意图如下:
# 使用make函数构造切片
我们上面都是基于数组来创建切片的,如果需要动态的创建一个切片,我们就需要使用内置的make函数,格式如下:
make ([]T, size, cap)
其中:
- T:切片的元素类型
- size:切片中元素的数量
- cap:切片的容量
举例:
// make()函数创建切片
fmt.Println()
var slices = make([]int, 4, 8)
//[0 0 0 0]
fmt.Println(slices)
// 长度:4, 容量8
fmt.Printf("长度:%d, 容量%d", len(slices), cap(slices))
需要注意的是,golang中没办法通过下标来给切片扩容,如果需要扩容,需要用到append
slices2 := []int{1,2,3,4}
slices2 = append(slices2, 5)
fmt.Println(slices2)
// 输出结果 [1 2 3 4 5]
同时切片还可以将两个切片进行合并
// 合并切片
slices3 := []int{6,7,8}
slices2 = append(slices2, slices3...)
fmt.Println(slices2)
// 输出结果 [1 2 3 4 5 6 7 8]
需要注意的是,切片会有一个扩容操作,当元素存放不下的时候,会将原来的容量扩大两倍
# 使用copy()函数复制切片
前面我们知道,切片就是引用数据类型
- 值类型:改变变量副本的时候,不会改变变量本身
- 引用类型:改变变量副本值的时候,会改变变量本身的值
如果我们需要改变切片的值,同时又不想影响到原来的切片,那么就需要用到copy函数
// 需要复制的切片
var slices4 = []int{1,2,3,4}
// 使用make函数创建一个切片
var slices5 = make([]int, len(slices4), len(slices4))
// 拷贝切片的值
copy(slices5, slices4)
// 修改切片
slices5[0] = 4
fmt.Println(slices4)
fmt.Println(slices5)
运行结果为
[1 2 3 4]
[4 2 3 4]
# 删除切片中的值
Go语言中并没有删除切片元素的专用方法,我们可以利用切片本身的特性来删除元素。代码如下
// 删除切片中的值
var slices6 = []int {0,1,2,3,4,5,6,7,8,9}
// 删除下标为1的值
slices6 = append(slices6[:1], slices6[2:]...)
fmt.Println(slices6)
运行结果
[0 2 3 4 5 6 7 8 9]
# 切片的排序算法以及sort包
编写一个简单的冒泡排序算法
func main() {
var numSlice = []int{9,8,7,6,5,4}
for i := 0; i < len(numSlice); i++ {
flag := false
for j := 0; j < len(numSlice) - i - 1; j++ {
if numSlice[j] > numSlice[j+1] {
var temp = numSlice[j+1]
numSlice[j+1] = numSlice[j]
numSlice[j] = temp
flag = true
}
}
if !flag {
break
}
}
fmt.Println(numSlice)
}
在来一个选择排序
// 编写选择排序
var numSlice2 = []int{9,8,7,6,5,4}
for i := 0; i < len(numSlice2); i++ {
for j := i + 1; j < len(numSlice2); j++ {
if numSlice2[i] > numSlice2[j] {
var temp = numSlice2[i]
numSlice2[i] = numSlice2[j]
numSlice2[j] = temp
}
}
}
fmt.Println(numSlice2)
对于int、float64 和 string数组或是切片的排序,go分别提供了sort.Ints()、sort.Float64s() 和 sort.Strings()函数,默认都是从小到大进行排序
var numSlice2 = []int{9,8,7,6,5,4}
sort.Ints(numSlice2)
fmt.Println(numSlice2)
# 降序排列
Golang的sort包可以使用 sort.Reverse(slic e) 来调换slice.Interface.Less,也就是比较函数,所以int、float64 和 string的逆序排序函数可以这样写
// 逆序排列
var numSlice4 = []int{9,8,4,5,1,7}
sort.Sort(sort.Reverse(sort.IntSlice(numSlice4)))
fmt.Println(numSlice4)